前言
什么是网络爬虫(也叫网络蜘蛛)?简单来说,是一种用来自动浏览万维网程序或脚本(网络爬虫的典型应用就是我们所熟知的搜索引擎)。既然如此,那么我们也可以写一个程序,用来自动浏览或者获取网页上的信息。本文将介绍利用python自带库编写一个简单的爬虫程序来获取网络信息。
准备
本次爬取实例可能涉及以下知识:
- python基础知识
- urllib库使用
- http基本知识
- html/js基本知识
- 正则表达式
环境准备:
- linux(windows基本适用)
- python3
- chrome浏览器
爬取目标
本次爬取的目标是知乎话题下的图片。
分析
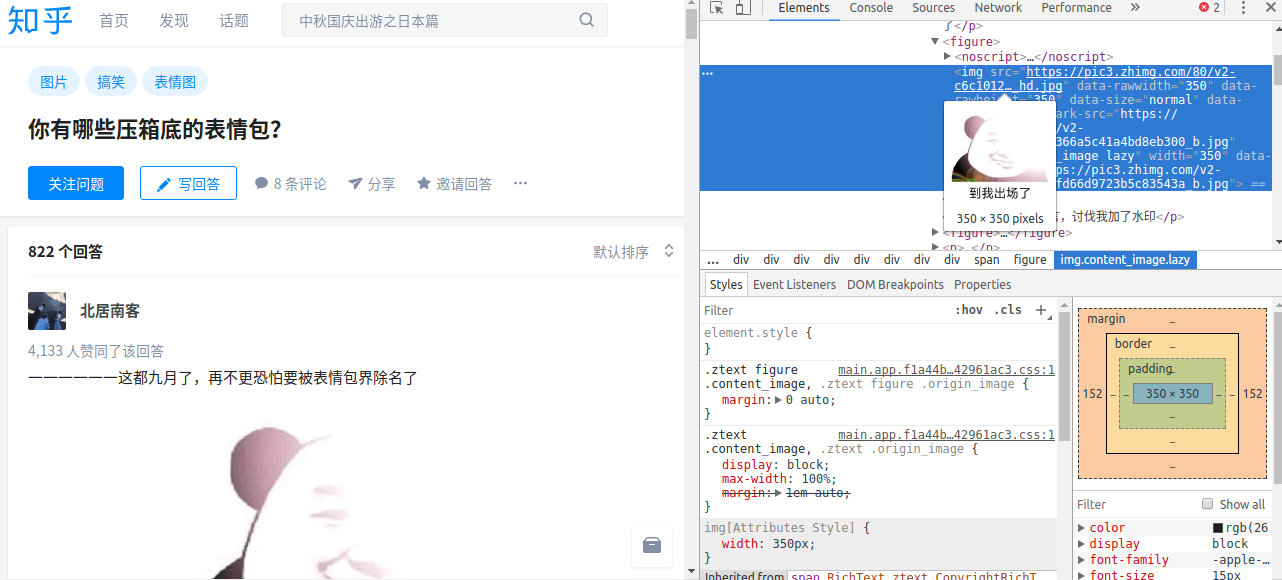
以知乎话题你有哪些压箱底的表情包?为例。
用chrome浏览器打开该链接。鼠标右键-检查元素,在elements页移动鼠标,当鼠标移动到某元素时,页面会被选中,因此我们可以找到第一张图片的img标签,而在标签中,我们可以找到图片的url地址,复制url地址,在浏览器打开,我们就看到了需要下载的表情包了。
至此,整体思路就很简单了:访问话题页—找到img标签—获取图片url地址—下载图片。
代码
1 | #!/usr/bin/python3 |
运行
有两个参数,第一个参数是url,即话题的链接,第二个参数是所要保存图片的路径。
在linux下运行1
./getZhiHuImage.py https://www.zhihu.com/question/48132860 ./test
将会在目的目录下发现下载好的图片。

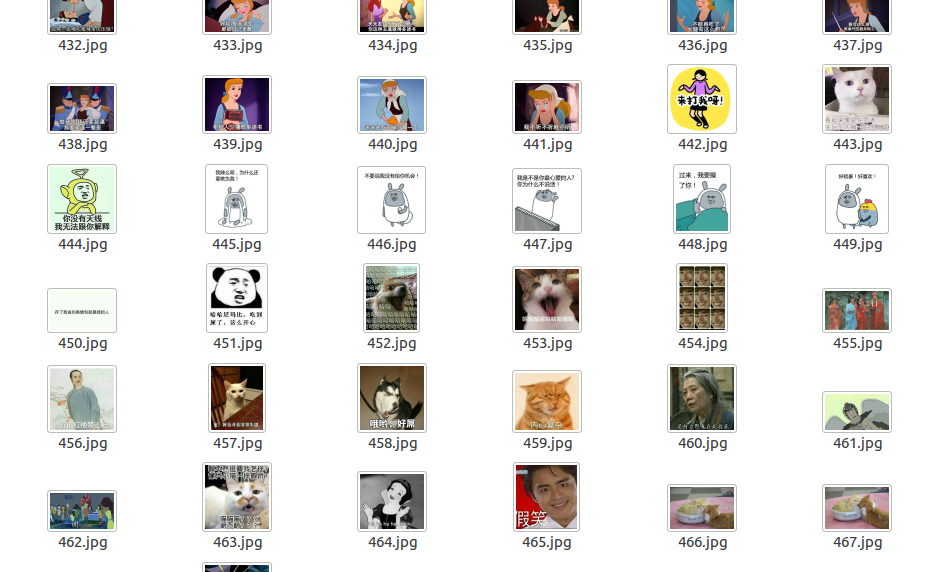
最后说两句
本文仅简单利用了python自带urllib库完成了话题图片的获取工作,但更多时候,爬取网络资源要更困难得的多,要获取的内容也不像本文例子中那么明显易得到,比如可能需要模拟登录,验证码识别,伪装成浏览器,去重等等,这里不再展开。但是Python中自带urllib及urllib2库,基本上能满足一般的页面抓取了。
表情包地址:链接: https://pan.baidu.com/s/1Xp-QT5eAn_2TqGeJ3UxuiA 密码: 3y9k


